大话测试数据(一)
转自: 的
2015-11-17、
目录:
测试数据在整个测试过程中扮演着极为重要的角色,但是它却像个没有星象的演员,明明至少是男二号,但总是被观众忽略。在测试过程中,我们往往在测试计划阶段就忽略了测试数据,在起先没有给测试数据的设计、准备留出足够的时间,投入足够的精力,到了测试执行阶段追悔莫及。只有吃过大亏的测试人员,才会在下一个测试开始的初期就认真的对待它。楼主也算是吃过亏的人。因此在现在经手的测试工作中,总会提着测试数据这根弦。今天一个网上的一个同学问了一个关于测试数据的问题,随手回答了一下以后,发现自己其实已经积累了一些经验了。现在把它们总结出来,供大家讨论。欢迎提出各种建议和各种问题,我会试着作出解答。
1 测试数据为什么重要
1.最浅显的道理:说白了测试用例的执行工作主要是做一些输入操作,然后观察输出。测试数据就是输入的内容,没有测试数据,你咋执行用例?
2.测试数据是测试设计的重要组成部分,测试用例的有效性严重依赖测试数据的选取或者设计,要记住测试的本质是抽样,样品的选取其实是一门深奥的科学,有学过统计学的同学会深切明白这个道理。
3.没有把测试数据这一块儿理顺,良好的自动化测试简直是空谈。试想,测试自动化采取的最普遍默模式就是“录制-回放”模式,如果搞不定数据,回放基本上会失败,自动化验证自然也就无法有效完成了。
4.测试数据能够启发测试设计。做测试多的同学都会有过选取一组测试用例后来了感觉发现自己思如泉涌的经历。
5.如果是已上线系统,或者生命周期较长的系统,从生产系统上log下来的数据可以很好的指导测试。(通过一些统计可以帮助识别那些业务重要,为能够制定正确的测试策略提供重要信息;对数据做pattern分析的话可以用于补充测试场景、用例,同样十分有益;这些数据还可以在测试中进行复用)。
6.其它种种好处。。。
2 测试数据的分类
我们可以从多个维度对测试数据进行分类,下面讲一下我的分类方式:
2.1 从测试数据的生命周期角度划分
可以将测试数据分为:稳定和数据、可消耗的数据和混合类型数据
- 稳定的数据:在一轮/多轮测试执行过程中几乎不会发生变化的数据,如常见的电商系统中的一些基础数据--城市,邮政编码,一些商品的属性,如衣服尺寸码等。
- 可消耗数据:测试执行完某个步骤后,数据发生不可逆改变,或者发生逆转操作需要耗费大量精力的改变。这类数据的例子有:商品的库存,票务系统里的票,要被 夜维程序删除的过期数据,网络数据包等等。
- 混合类型数据:某些数据是复合型数据,如XML结构或者Json结构的某些数据,一条数据中的一部分是稳定的数据,另一部分是可消耗数据,这样的例子其实很常见,一般这样的数据会被当做可消耗数据来处理。
从数据是否可构造的角度来看可以将测试数据分为:可直接构造数据和需要间接获取的数据。
- 可直接构造的数据:常见系统的大部分数据都可以直接被构造,通过操作系统本身,或者通过调用某些接口(SQL也算接口)插入数据,有时候甚至这些数据就是文本,直接准备好他们就行了。
- 需要间接获取的数据:手工制造成本太高(理论上我们可以制造所有测试数据,但有时候就是成本太高),如某些以二进制存储的含有信息的数据(被序列化的数据),某些非文本数据,例如音频数据,视频数据,传感器上传过来的极为复杂的带有某些pattern的数据。举个很好玩的例子,见过“猎曲奇兵”这款软件么?偶然听到一首歌,打开猎曲奇兵,十秒钟左右它就能告诉你是哪一首歌。你基本上无法自己创造一条有效的测试数据,除非你是张学友或者Lady Gaga。
2.2 从业务角度来看数据划分
可以分为:合规数据、非合规数据、Fuzz数据
- 合规数据:望文生义,就是符合业务规则的数据,如能够通过校验的身份证号。
- 非合规数据:显然就是不符合业务规则的数据,当你被要求输入注册邮箱的时候,你给出这样的输入:skytraveler@@163.com 显然不会合规。
- Fuzz数据:Fuzz数据主要是利用一些工具生成的乱七八糟的数据,主要用于系统稳定性测试和安全测试。这是一个大话题,有兴趣的话推荐看《模糊测试》这本好书。
2.3 从测试数据来源来划分
可以分为:生产dump数据,自己生成的数据
上面的分类其实并不是很准确,但是分类就是为了帮助更高效的解决问题。接下来我会讲解对于上面类型的数据我是如何来处理的。
3 测试数据的生成过程
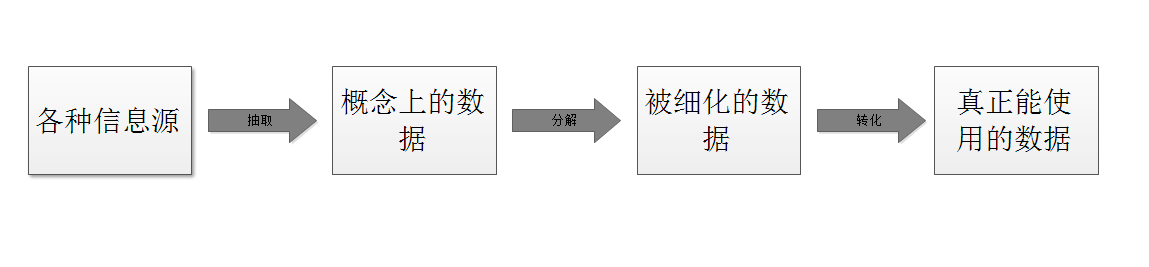
概念上的数据:也就是抽象的数据,例如,你的被测物是一款收银软件,你知道每笔交易结束后,需要生成一张“发票”,见过发票的你大概知道 它长什么样子(如下图),“发票”就是概念上的数据,但它并不能直接使用。

被细化了的数据:也就是具体的数据项。拿到发票后,我们还要分析发票里到底有哪些数据,经过需求的获取及分析,我们知道发票包含:发票日期,发票代码,付款方,收款方,金额,防伪码,二维码等。同时我们也知道了这些数据的规约,例如,发票的日期格式是:yyyy年mm月dd日。
真正能使用的数据:我们知道了数据的细节,就可以按照这些细节准备被测系统能够识别和接受的数据了。例如,上面所说的发票付款方,收款方,真正的操作可能会直接在GUI中输入,或者可以调用某些接口,或者可以直接插入数据库。这时候你要做的就是,让你的数据变得能用起来。
从上面的解释可以得到测试数据从被识别,到能够被使用的大体步骤:
事实上,实际工作中,测试数据的准备远远不是这么简单。很多时候上面的每一步骤的推动都是一个艰苦的过程。搞定它需要柯南一样抽丝剥茧的能力和工匠的细致和耐心。我会尽量在后续的文章中讲述一些我的经验。